
代码随想录 二叉树:迭代遍历
题目描述
使用迭代法实现二叉树的 前、中、后序遍历。
思路
递归法中的隐含的 “栈” 做了什么
我们知道使用递归法可以实现前中后序遍历,而递归的本质就是栈,每次函数调用都会把函数的参数,局部变量和返回地址等上下文信息压入栈中,然后递归返回时从栈顶弹出上一次递归的各项参数。
对比递归的前序遍历
void preorder(TreeNode* node, vector<int>& result) {
if (node == nullptr) {
return;
}
result.push_back(node->val); // 中
preorder(node->left, result); // 左 等同于 把左节点压入栈中处理。
preorder(node->right, result); // 右 等同于把右节点压入栈中处理。
}
vector<int> preorderTraversal(TreeNode* root) {
vector<int> result;
preorder(root, result);
return result;
}对于递归来说,代码顺序是中左右,每个函数内部是中左右的顺序。
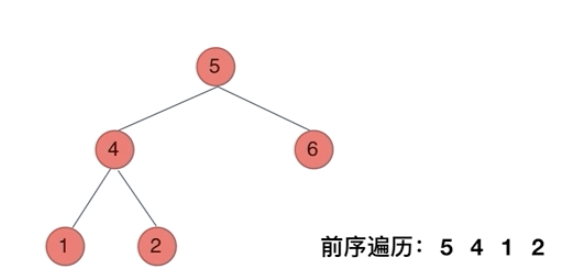
上面举例,递归时隐含的栈是这样的(其中每一个元素是一个preorder函数作用域)是这样的,将一个节点压入栈,立马将元素添加到结果数组中,实现遍历,遍历完当前节点后要往左节点走,压入一个 左节点的preorder 函数栈帧。
想象一下,这是一个二叉树的先序遍历:
A
/ \
B C
/ \
D E我们来模拟一下 preorder 递归函数执行时,调用栈(也就是你说的“隐含的栈”)的变化过程:
初始调用:
preorder(A)- 调用栈:
[preorder(A)] - 输出:
[A]
- 调用栈:
preorder(A)中调用preorder(B)- 调用栈:
[preorder(A), preorder(B)] - 输出:
[A, B]
- 调用栈:
preorder(B)中调用preorder(D)- 调用栈:
[preorder(A), preorder(B), preorder(D)] - 输出:
[A, B, D]
- 调用栈:
preorder(D)中调用preorder(nullptr)(左子)- 调用栈:
[preorder(A), preorder(B), preorder(D), preorder(nullptr)] preorder(nullptr)遇到基线条件,返回。- 调用栈:
[preorder(A), preorder(B), preorder(D)]
- 调用栈:
preorder(D)中调用preorder(nullptr)(右子)- 调用栈:
[preorder(A), preorder(B), preorder(D), preorder(nullptr)] preorder(nullptr)遇到基线条件,返回。- 调用栈:
[preorder(A), preorder(B), preorder(D)]
- 调用栈:
preorder(D)执行完毕,返回- 调用栈:
[preorder(A), preorder(B)]
- 调用栈:
preorder(B)中调用preorder(E)- 调用栈:
[preorder(A), preorder(B), preorder(E)] - 输出:
[A, B, D, E]
- 调用栈:
preorder(E)中调用preorder(nullptr)(左子)- 调用栈:
[preorder(A), preorder(B), preorder(E), preorder(nullptr)] preorder(nullptr)遇到基线条件,返回。- 调用栈:
[preorder(A), preorder(B), preorder(E)]
- 调用栈:
preorder(E)中调用preorder(nullptr)(右子)- 调用栈:
[preorder(A), preorder(B), preorder(E), preorder(nullptr)] preorder(nullptr)遇到基线条件,返回。- 调用栈:
[preorder(A), preorder(B), preorder(E)]
- 调用栈:
preorder(E)执行完毕,返回- 调用栈:
[preorder(A), preorder(B)]
- 调用栈:
preorder(B)执行完毕,返回- 调用栈:
[preorder(A)]
- 调用栈:
preorder(A)中调用preorder(C)- 调用栈:
[preorder(A), preorder(C)] - 输出:
[A, B, D, E, C]
- 调用栈:
preorder(C)中调用preorder(nullptr)(左子)- 调用栈:
[preorder(A), preorder(C), preorder(nullptr)] preorder(nullptr)遇到基线条件,返回。- 调用栈:
[preorder(A), preorder(C)]
- 调用栈:
preorder(C)中调用preorder(nullptr)(右子)- 调用栈:
[preorder(A), preorder(C), preorder(nullptr)] preorder(nullptr)遇到基线条件,返回。- 调用栈:
[preorder(A), preorder(C)]
- 调用栈:
preorder(C)执行完毕,返回- 调用栈:
[preorder(A)]
- 调用栈:
preorder(A)执行完毕,返回- 调用栈:
[]
- 调用栈:
我们以先序遍历为例,它的顺序是“根 - 左 - 右”。当递归函数在“隐含的栈”中执行时,这个顺序是如何体现的呢?
- “根”的体现:在压栈后立即处理
- “左”的体现:通过递归调用优先深入
- “右”的体现:在左子树处理完毕后回溯
**压栈:**每当一个节点被访问(先序遍历的“根”),其对应的函数就会被压入栈。
出栈(回溯):当一个子树完全遍历完毕后,其对应的函数会从栈中弹出。
迭代法如何模拟递归法行为
递归方法的本质是系统自动为我们维护了一个“调用栈”,每次函数调用就是压栈,每次函数返回就是弹栈。迭代法就是模拟这个系统行为,用一个显式的 std::stack 来代替隐式的系统调用栈 🪜。
迭代法和递归处理顺序的思路有所不同。
我们回忆一下递归先序遍历的顺序:“根 - 左 - 右”。
处理“根”:
- 递归:在函数刚被调用(压栈)后,立即处理
node->val。 - 迭代:我们从栈中取出一个节点
node(st.top(); st.pop();),然后立即将其值node->val加入到result中。这正是对“根”的访问。
- 递归:在函数刚被调用(压栈)后,立即处理
处理“左”和“右”: 这是迭代法最关键,也是最容易混淆的地方。回忆一下递归中,我们是先
preorder(node->left, ...),再preorder(node->right, ...)。但由于系统栈是“后进先出”的,为了让左子树先被处理,我们需要采取一些策略。递归的逻辑:
cpppreorder(node->left, result); // 先调用左子 preorder(node->right, result); // 再调用右子当
preorder(node->left)被调用时,它会压入栈,然后执行,直到完成。完成后,程序才会回到preorder(node)的栈帧,接着调用preorder(node->right)。迭代法的模拟: 因为栈是“后进先出”(LIFO),为了让
left先于right被处理(即left先出栈),我们必须先将right压入栈,再将left压入栈。这样,left就会在栈顶,下次循环时会先被取出并处理 。cppif(node->right) st.push(node->right); // 将非空右子节点推入栈中 if(node->left) st.push(node->left); // 将非空左子节点推入栈中 (在右子之后压入,所以它会先弹出)这正是利用了栈的特性来反转入栈顺序,以实现我们想要的先序遍历顺序(根 -> 左 -> 右)。
另外需要注意的是递归法可以处理空节点,因为有终止条件,而迭代法需要弹出栈顶元素处理节点,因此必须保证栈不为空,这意味着我们不能把空节点放到栈中。
迭代法实现前序遍历
class Solution {
public:
vector<int> preorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if(root == nullptr) return result;
st.push(root);
while(!st.empty()){
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if(node->right) st.push(node->right);
if(node->left) st.push(node->left);
}
return result;
}
};迭代法实现后序遍历
后序遍历只需要稍微调整前序遍历的代码
class Solution {
public:
vector<int> postorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
vector<int> result;
if (root == NULL) return result;
st.push(root);
while (!st.empty()) {
TreeNode* node = st.top();
st.pop();
result.push_back(node->val);
if (node->left) st.push(node->left); // 相对于前序遍历,这更改一下入栈顺序 (空节点不入栈)
if (node->right) st.push(node->right); // 空节点不入栈
}
reverse(result.begin(), result.end()); // 将结果反转之后就是左右中的顺序了
return result;
}
};中序遍历(迭代法)
前序遍历的代码,不能和中序遍历通用,因为前序遍历的顺序是中左右,先访问的元素是中间节点,要处理的元素也是中间节点,所以刚刚才能写出相对简洁的代码,因为要访问的元素和要处理的元素顺序是一致的,都是中间节点。
你看
while (!st.empty()) {
TreeNode* node = st.top(); //访问元素
st.pop();
result.push_back(node->val); //处理元素
if (node->right) st.push(node->right);
if (node->left) st.push(node->left);
}中序遍历(迭代法)
而中序遍历,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
那么在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。
class Solution {
public:
vector<int> inorderTraversal(TreeNode* root) {
stack<TreeNode*> st;
TreeNode* cur = root;
vector<int> result;
while(cur != nullptr || !st.empty()){ // 1.很明显代码中有st.top(),所以不能为空。2.虽然内层条件 cur 可能为空可能不为空,好像这里无所谓,但是会出现:根节点的左子树全部处理完毕,此时栈是空的,但是右子树还有内容,指针还指向右子树,还需要继续向下探索。
if(cur != nullptr){ // 指针指向非空节点,就加入到栈中,这是遍历
st.push(cur); // 加入栈中
cur = cur->left; // 指针往下遍历
} else{
TreeNode* node = st.top();
st.pop();
result.push_back(node->val); // 取出栈顶元素,添加到结果,此时指针cur 访问节点 和 处理节点 node 是不一样的。
cur = node->right; //指针遍历右子树
}
}
return result;
}
};